ContractionPPO Architecture
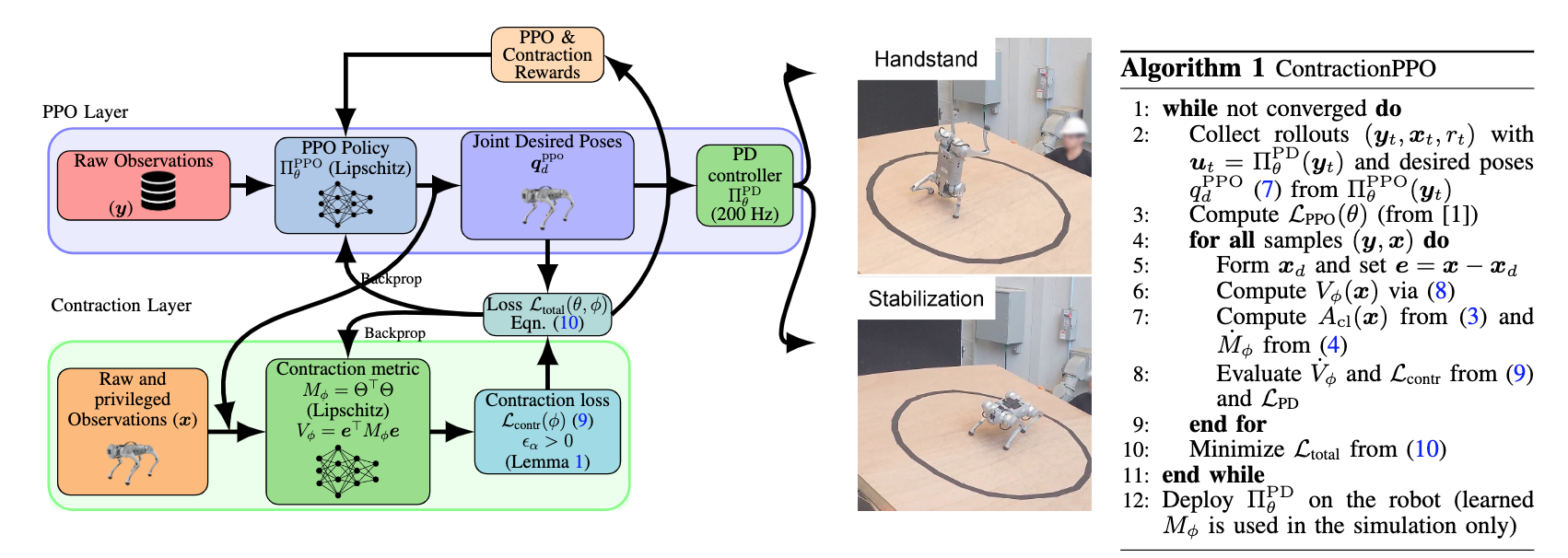
Architecture of ContractionPPO. The PPO policy processes raw observations $\mathbf{o}$ and outputs desired joint poses $\mathbf{x}_d$, which are executed by a low-level PD controller. In parallel, the contraction metric MLP $M_\phi$ receives privileged and raw observations $\hat{\mathbf{x}}$ and outputs a positive definite metric $M_\phi = \Theta^\top \Theta$. The contraction loss is evaluated using the Lyapunov condition $\dot{V} + \alpha V \leq -\epsilon_\alpha$, where $\alpha$ specifies the desired contraction rate and $\epsilon_\alpha$ quantifies the approximation margin between the learned value function $V_\phi$ and the true contraction Lyapunov function $V$. A larger $\alpha$ leads to faster convergence guarantees but also requires a larger $\epsilon_\alpha$, making optimization more challenging. This joint training setup ensures that the policy not only maximizes task reward but also satisfies certifiable incremental stability guarantees during locomotion.
Classical reinforcement learning can discover highly capable locomotion policies, but it typically does not provide formal guarantees on how the robot will behave under perturbations, modeling error, or observation noise. Contraction theory addresses this by certifying that nearby trajectories of the closed-loop system converge exponentially toward one another.
In ContractionPPO, this idea is embedded directly into training through a learned state-dependent contraction metric. The result is a controller that is not only performant in nominal conditions, but is also driven toward provably stable and robust behavior throughout learning.
ContractionPPO Deployment
Comparisons with Baseline Methods
ContractionPPO
TumblerNet
Rapid Motor Adaptation
PPO
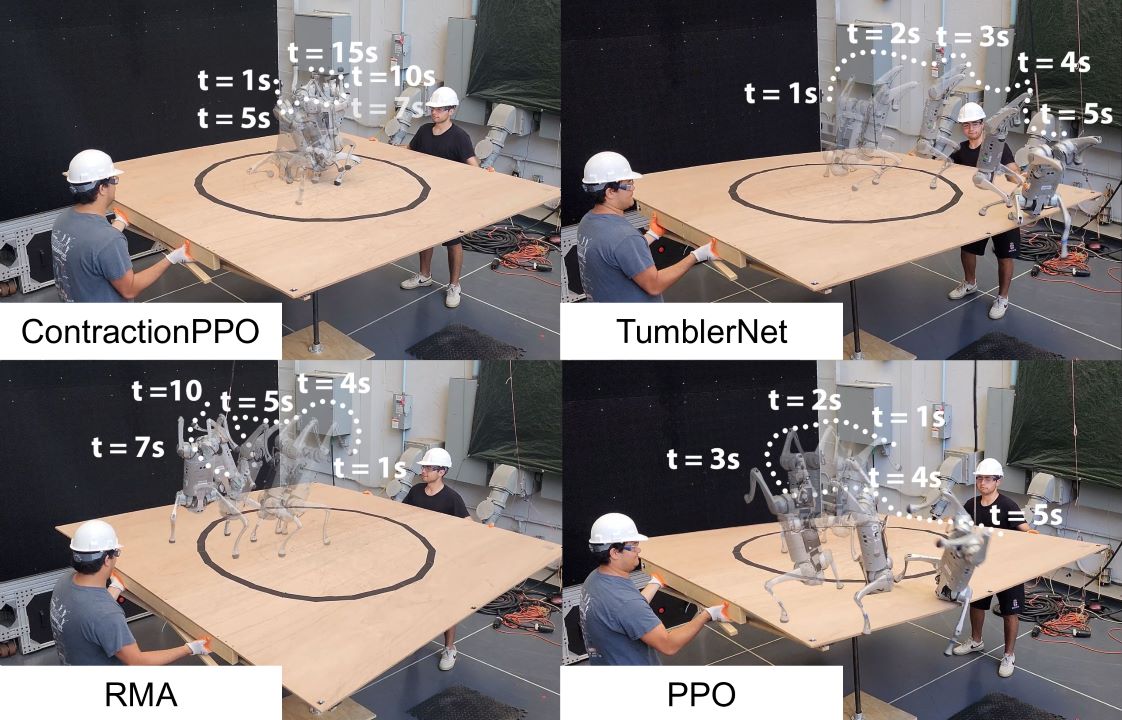
Comparison of trajectories for quadruped handstand using ContractionPPO (ours), TumblerNet, RMA and PPO where robots (for all baseline algorithms) were trained with identical reward functions that encourage remaining close to their initial position. While PPO, TumblerNet and RMA leaves the region and ultimately fails to remain on platform, ContractionPPO guarantees that the robot lie inside the circle (marked in black). This illustrates the core advantage of our approach i.e., provably stable and robust behavior.
Wind Experiments
Wind Speed: 4.8m/s
Wind Speed: 6.4m/s
Wind Speed: 8.0m/s
Wind Speed: 9.6m/s
*Wind disturbances were never seen during training
Humanoid stabilization

Quadruped trajectories during handstand under wind disturbances of varying magnitudes. As the disturbance intensity increases, transient deviations from the initial position become more evident. Note that ContractionPPO was never trained on external disturbances. Despite this, ContractionPPO policy ensures bounded trajectories and lies inside the circle marked by the black curve. This highlights the robustness and incremental stability guarantee of ContractionPPO, even under strong external perturbations.
Results
Comparison of methods across control points and violations. Numbers represent failure ratio over all episodes. Combined is 2500 episodes, and each control point is 500. Lower is better.